Developer Experience in the Agentic Era: Make the Loop as Fast as the Generator
A concrete engineering field guide for matching agent speed at the team level.

Generation is no longer the constraint. Everything downstream of it is: getting the agent the right context, verifying its output, integrating it without a pile-up, releasing it safely, operating it in production, and turning what it did into something the team learns from. Each link has to run near generation speed or it becomes the bottleneck and your engineers sit in the queue.
"Agents amplify whatever your platform already is. Weak tests, slow builds, and thin docs do not get absorbed by a capable model, they get multiplied by it."
Two forces recur, and almost every lever below is one or the other: shorten feedback latency, and make trust automatic so a human is not the gate on every change.
The dev-ex loop & the 13 levers you can pull
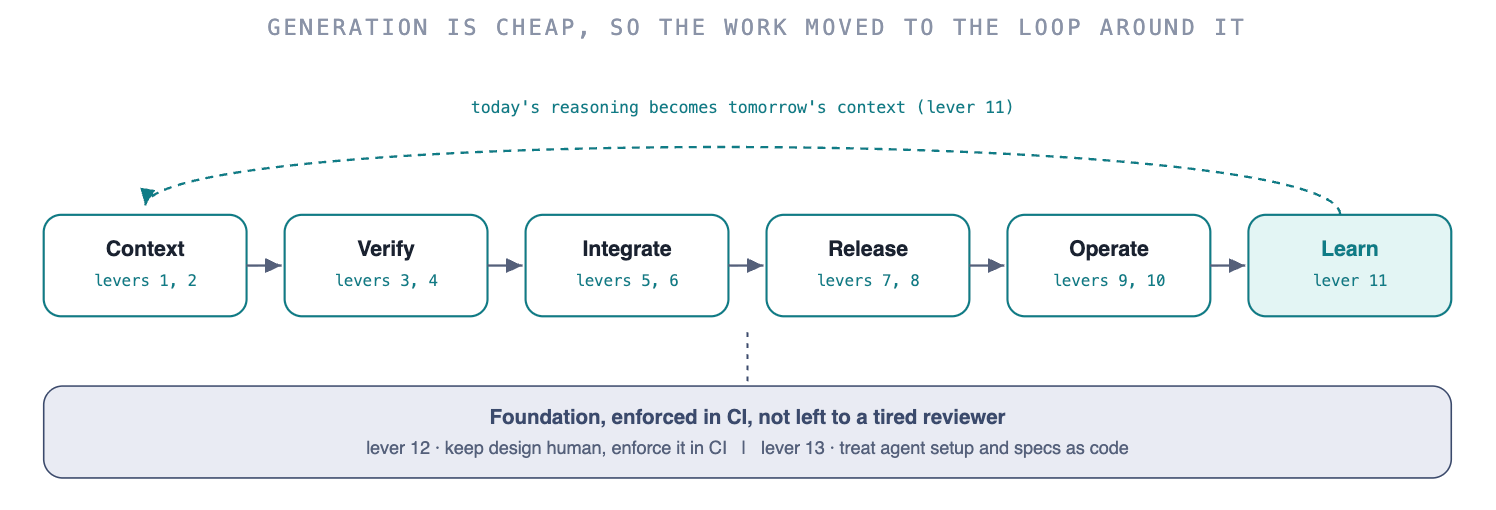
The pragmatic on-ramp
Before we go on further & overwhelm you with the details, here is a possible phased approach to setting up your platform for AI native engineering.
You cannot stand up all thirteen at once, and trying is how the platform-engineering tax crushes your velocity before the agentic gains land. Treat the levers as a maturity model and start here.
Phase 1 · Days
Stop the bleeding
Write your CLAUDE.md: stack, architecture layers, the absolute “do nots”. Lever 1
Give the agent one make verify: linter, type check, and hermetic tests in under 60 seconds. Lever 3
Phase 2 · Weeks
Unclog the queue
Fix the build so CI returns red or green in seconds, not minutes: layer cache, affected-only builds. Lever 4
Tier PRs by blast radius behind a merge queue, so a one-line schema change is not reviewed like a CSS tweak. Lever 6
Phase 3 · Months
The agentic platform
Decouple deploy from release: flags, canaries, and signal-gated promotion. Levers 7 & 8
Brokered, read-broad write-gated credentials so agents can safely run ops in production. Lever 10
Illustrative, not gospel. The point is the sequence: stop the bleeding before you build the platform, or the tooling tax arrives before the payoff does.
Without further ado, the 13 levers
1 Feed the agent context, so it is right the first time
In short
Seed context before generation with a self-describing CLAUDE.md, current docs via Context7, and paved-road templates, while staying honest that a real codebase is messier than any manual, and that managing context live is the next lever, not this one.
The cheapest defect is the one prevented before generation. An agent with the wrong context does not fail loudly, it produces plausible, confident, wrong code that costs a full review cycle to reject. This lever is the static half: what you set up before the agent starts. Three moves, in order of leverage.
Move 1 Make the repo describe itself
A root CLAUDE.md (or AGENTS.md), plus recursive ones inside the folders that have their own invariants, read every session. The discipline is what it excludes: an operating manual, not documentation. Stack, exact commands, architectural invariants, sharp edges. Not prose the agent will not act on.
Move 2 Give it current docs, not training memory
A model's knowledge of a fast-moving library is months stale and silently wrong, the single most common source of confident bad output. Context7 (Upstash) fetches version-specific docs at query time and injects them, so the agent writes against the API you actually depend on.
Move 3 Lay paved roads
cookiecutter or copier templates plus a few reference implementations it is told to imitate. Output variance is what you pay for in review, so every blessed pattern it copies instead of inventing is review time you do not spend.
# CLAUDE.md
## Stack
Python 3.12, FastAPI, Postgres, pytest. Package manager: uv.
## Conventions
- Types required (mypy --strict). Format and lint with ruff.
- No business logic in routers; it lives in services/.
- Tests sit next to code, hermetic, no network.
## Commands
- install: uv sync | test: make test (<60s) | check: make check
## Architecture
Layers: api -> services -> repositories -> db. No upward imports.
## Do not
- Add a dependency without saying why in the PR.
- Touch migrations/ without flagging a human reviewer.For Context7, register https://mcp.context7.com/mcp with a CONTEXT7_API_KEY header, trigger it with "use context7" or set it to auto-invoke, and pin it to your lockfile versions. It runs across Claude Code, Codex, and Cursor. (github.com/upstash/context7)
⚠ Failure mode
Drift. A CLAUDE.md that describes last quarter's repo is worse than none, because the agent trusts it. Generate the volatile parts from source, the command list from your Makefile or pyproject.toml, the layer rules from the same config your linter enforces (lever 12), so the document cannot disagree with reality without breaking the build. Keep it short enough that staleness is obvious: a 60-line file gets corrected, a 600-line one rots in the dark.
Where this gets hard in a real codebase
Brownfield, not greenfield. A 600k-line monorepo or four tangled services will not fit one CLAUDE.md, and the truth is scattered, partly in people's heads, and contradicted by code mid-migration. You are making a dent, not writing a manual.
The manual lies. Conventions are aspirational, the architecture diagram is six months stale, and half the "do not" rules are violated in the very code the agent is reading. Feeding it the official story over the actual code produces a new kind of confident wrong, so when the two disagree, the code wins.
Docs are the easy third. Context7 fixes stale API signatures. It does nothing for the load-bearing hack you cannot touch, the service that looks dead but is not, or the customer who depends on the bug. That context lives nowhere a tool can fetch, so harvest it from incident history and PR archaeology and write it down.
This is seeding, not managing. Everything above happens before generation. What governs the agent mid-task, what is actually loaded, in what order, and what survives the session, is a different problem, and it is the next lever.
2 Engineer the context window as a managed resource
In short
Context is a finite budget you manage per task and per session, not a manual you write once. The levers are retrieval (load the right subset just in time), compaction and note-taking (as the window fills), sub-agents (isolate noisy work), durable memory (persist only what constrains future reasoning), and integrity (treat the window as an attack surface).
Lever 1 seeds context before generation. But context is not a document you author once. Anthropic defines context engineering as the strategies for curating and maintaining the optimal set of tokens during inference, and the hard part is dynamic: what is loaded right now, in what order, how much, what gets evicted, and what survives to the next session. A large system never fits the window, so the discipline is relevance and lifecycle, not completeness.
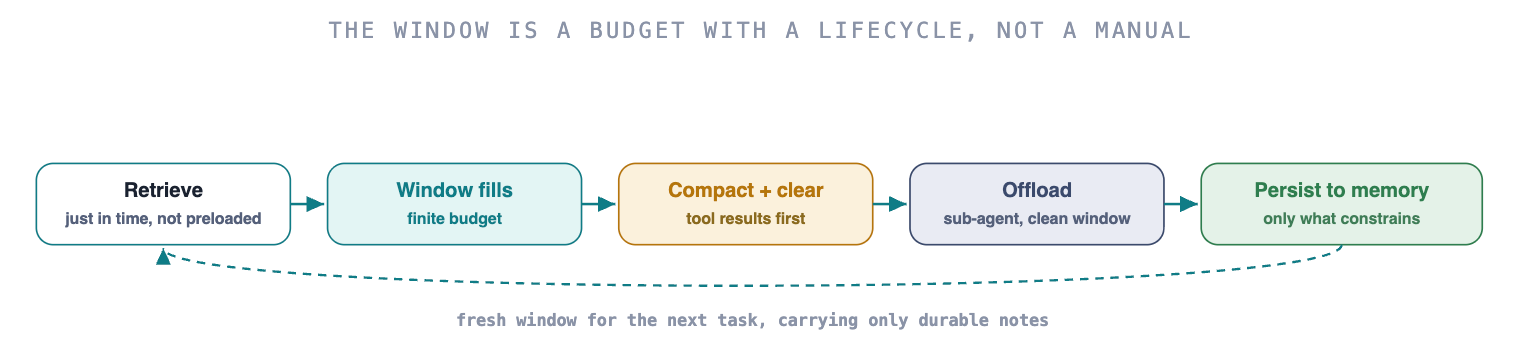
Six levers turn the window from a thing you fill into a thing you manage.
Retrieve just in time, do not preload. Let the agent pull the files, symbols, and history it needs for this task at runtime, agentic grep-and-read, a code-search MCP, embeddings over the repo, rather than stuffing the whole system in up front. Preloading burns budget and buries the relevant tokens; just-in-time retrieval keeps the window dense with what matters now.
Compact and clear as the window fills. Compaction summarizes a conversation nearing the limit and reinitializes a fresh window with the summary (/compact in Claude Code). The safest first cut is tool-result clearing: once a tool ran deep in history, the raw output rarely needs to stay, which Anthropic ships as a platform feature.
Offload to sub-agents with clean windows. A focused sub-agent does the noisy subtask in an isolated context and returns only the distilled result, so the main thread stays uncluttered. Same instinct as lever 10's isolation, applied to attention instead of credentials.
Persist only what constrains future reasoning. Durable memory, a NOTES.md, a memory tool, or a memory MCP, should hold decisions, failed approaches, and durable preferences, and nothing else. Anthropic's first-window pattern is an initializer agent that sets up the environment and the notes future agents will need.
Partition context across multiple agents. The orchestrator holds the plan and the shared invariants; workers get scoped slices; you define what passes at each handoff. An unstructured handoff is where half-built, undocumented state comes from, the next session inherits a feature half-implemented and has to guess what happened.
Treat the window as an attack surface. Untrusted content the agent reads, a log line, a fetched doc, a file, can carry instructions. This is the injection threat lever 10 contains at the credential boundary, seen from the context side: mark or quarantine untrusted spans, and never let fetched content issue commands.
⚠ Failure modes
Context rot: quality silently degrades as a session lengthens, so the fix is a fresh window per task, not a heroic single thread.
One-shotting: the agent tries to do too much, runs out mid-task, and leaves the next session guessing.
Over-compaction: you summarize away the load-bearing detail, because lossiness is a spectrum, not a binary.
Memory pollution: a durable store that accretes noise until it poisons every future run.
3 Fail fast and local, before the PR ever exists
In short
Catch failures in the agent's own loop in seconds, and make the test suite an oracle you can trust by quarantining flaky tests and mutation-testing the critical paths.
The location of a failure determines its cost. Every technique here moves failures left along this gradient:

Give the agent one command to verify itself before it ever opens a PR:
# Makefile — the agent runs this before opening a PR
verify:
ruff check . && ruff format --check .
mypy --strict .
pytest -q --maxfail=1 # hermetic unit tests, <60s
semgrep --error --config auto # SAST
gitleaks detect --no-banner # secretsThese deterministic guardrails each convert a category of mistakes from "a human might notice" into "the build mechanically refuses." Make them blocking, not advisory: a non-required check is one the queue learns to ignore.
The hard part is the suite’s credibility, and there are two distinct threats to it.
Threat 1 · Flakiness
An agent cannot tell a flaky failure from a real one, so it thrashes fixing a test that was never broken, or learns to retry until green, which trains it to ignore real failures. Detect with rerun-on-failure tooling (pytest-rerunfailures) or a nightly N-run job, quarantine out of the blocking path, track the flaky rate with an owner, fix as production work. A 99%-reliable suite is far less than 99% useful, the 1% teaches the wrong lesson.
Threat 2 · The agent writes its own tests
A green suite can mean weak assertions, not correct code, and an agent optimizing to pass will write tests that cannot fail. Spot-check with mutation testing (mutmut or cosmic-ray, Stryker elsewhere): it injects faults and confirms the tests catch them. Run it on critical paths only (auth, money, data integrity), track the mutation score, and require a human eye on the tests for high-blast-radius changes.
Make environments cheap and reproducible: devcontainers plus ephemeral preview environments (per-PR Kubernetes namespaces on EKS, or Okteto, Render, fly.io). Pin everything for hermetic builds, because nondeterminism is to an agent what a flaky test is. Then order CI to fail fast: cheapest and likeliest-to-fail checks first, the rest parallel, first red surfaced immediately. The metric is time-to-first-signal, not total pipeline time.
4 Fix the build, not just the tests
In short
On a fast agent - the build, not the tests, is usually the wall: cache image layers, build only what changed, and derive PR builds from a digest-pinned base image.
On many pipelines the wall-clock time is dominated by building and pushing artifacts, container images especially, and that cost is paid on every iteration. Three layers of fix.
Layer 1: cache the image layers and reuse them across runs.
# docker buildx — registry layer cache
docker buildx build \
--cache-from type=registry,ref=$IMG:cache \
--cache-to type=registry,ref=$IMG:cache,mode=max \
-t $IMG:$SHA .Layer 2: build only what changed, which on a monorepo is the difference between a 2-minute and a 40-minute run.
# affected-only builds
pants --changed-since=origin/main test lint # Pants: only what changed
bazel test //... On AWS and GitHub the building blocks are already there. Point type=registry at ECR or GHCR, or use the GitHub Actions cache backend (--cache-to type=gha); for large artifacts use the S3 backend (type=s3). For dependency and task caches, actions/cache covers most needs, and a self-hosted Pants or Bazel remote cache backed by S3 means the second person to build never rebuilds the first's work.
Layer 3: bake a master base image. Dependency install, not compilation, is usually the slow step. Build a base from main with the runtime and dependencies baked in, push to ECR, and have PR builds derive FROM it so they rebuild only the application layer. This is often the single biggest win on top of layer caching.
⚠ Two failure modes
Drift and stale CVEs. A frozen base diverges from what PRs need and quietly stops getting security patches. Both are solved the same way: rebuild the base on a schedule and whenever the lockfile changes, pin it by digest for reproducibility, and scan it on a schedule.
5 Monorepos are underpriced, and the tooling is the point
In short
A monorepo lowers review variance and enables atomic cross-cutting changes, but only if you pay for the cache, affected-graph, and merge-queue tooling it demands.
This one is a judgment call, not a config, so it stays short. Agents sharpen the monorepo case three ways: one place to read context and one set of conventions, which lowers the output variance you pay for in review; atomic cross-cutting changes, so the agent updates a shared library and every consumer in one reviewable PR instead of the multi-repo version dance it gets wrong; and the affected-graph from lever 4.
The honest cost is that monorepos demand real tooling to scale, remote cache, affected-only builds, CODEOWNERS, and a merge queue, and the failure mode is the structure without the tooling, which is slow builds multiplied by agent volume. But that list is identical to what agent velocity needs anyway, so it is the same investment, not a second one. You do not have to boil the ocean: the migration that pays off first is the affected-graph, because it makes everything else cheap.
6 Integrate through a queue, and tier by blast radius, not by diff size
In short
Serialize merges through a queue so main stays green, and route review by real blast radius (reversibility, surface, exposure) rather than by how many lines changed.
This is where individual speed goes to die. Run a merge queue (GitHub merge queue, Graphite, Mergify) so concurrent PRs against a fast-moving main are serialized and main stays green. It solves the "passed CI an hour ago, conflicts now" race, where two independently-green PRs are mutually incompatible, by rebuilding and retesting each change against the main it will actually land on. Two things to design: speculative execution, testing batched PRs in parallel so throughput does not collapse, and queue hygiene, because a single flaky test poisons everything behind it, which is why lever 3 is a prerequisite.
Keep PRs under ~400 lines and stack them. Make every PR self-describing with a fixed template:
-- PR template
## What & why
## Risk (reversibility / surface / exposure)
## Tests run / evidence
## Diff vs the approved planBlast radius is the organizing idea for the rest of this guide, and low/med/high is too coarse to act on. Tier on three independent dimensions:
Reversibility Undoable with a flag flip, or has it changed state (data, schema, a published message) that cannot be taken back?
Surface One service, or a shared interface every consumer depends on?
Exposure An internal tool, or the auth, money, or PII paths?
The consequence: a change can be tiny in lines and catastrophic in blast radius, a one-line edit to token validation, so stop using diff size as the proxy for risk. Let the tiers drive different machinery.
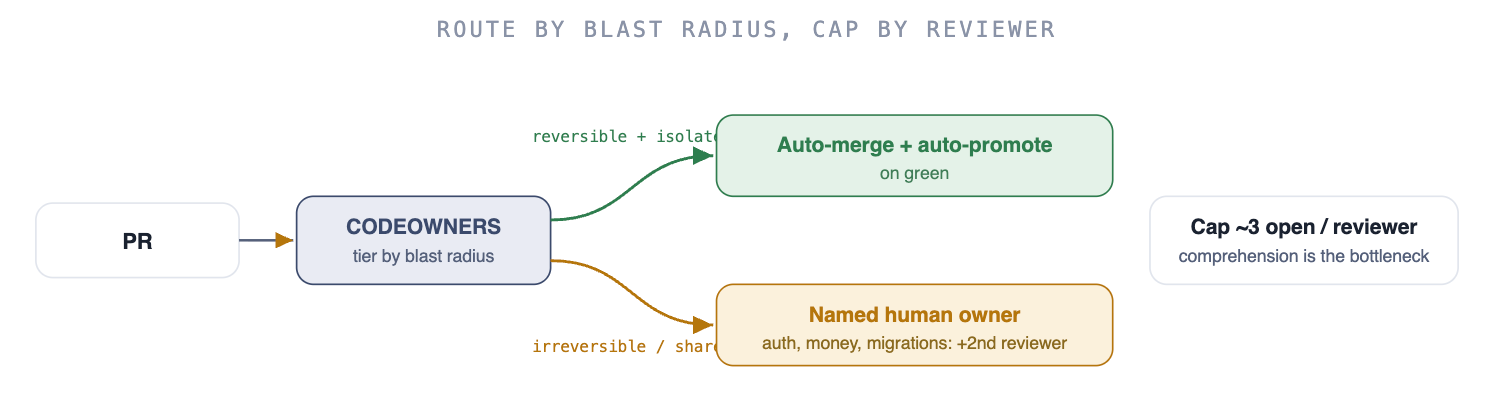
⚠ Failure mode
Tier inflation. Everything drifts into high-risk because no one wants to own a mistake, which silently collapses you back to human-reviews-everything. The trap that feeds it is gating at the PR, where the agent has already chosen the approach; the cheaper gate is at the plan (lever 12). Counter inflation by making the low tier genuinely safe, cheap rollback, flags, small surface, so choosing it is not a gamble.
7 Release behind a safety floor, so speed is not scary
In short
Make damage cheap to undo with flags, canaries, and auto-rollback, and remember a flag flip reverts code, not state, so make schema and data changes backward-compatible.
A fast merge feels dangerous because it can do real damage, so make damage cheap to undo rather than slow the merge. The mechanism is decoupling deploy from release: ship the code to production dark, then turn it on for traffic separately, so "deployed" and "live" are two events you control independently. Put changes behind flags (OpenFeature as the standard, with LaunchDarkly, Unleash, or Flagsmith behind it), roll out with canaries (Argo Rollouts or Flagger on EKS), and wire automatic rollback to an SLO or error-budget breach. When a bad change costs a flag flip instead of an incident, fast becomes fine.
⚠ The catch agents miss
A flag flip reverts code, not state. A migration, a consumed message, a sent email, a third-party write, none flip back, and agents reach for them casually. So make state changes backward-compatible by construction. For schema, that is expand-contract, each step independently reversible:

This is exactly where lever 6's tiering should force a human owner: step 5 is the one that leaves the reversible world.
8 Promote automatically through environments, human by exception
In short
Promote through environments automatically, each step gated on real signals rather than a human click, and pull the developer in only when a gate halts.
A fast, validated build should not wait on a human to walk it to production. Once it passes in an isolated, production-like environment, promotion runs automatically, each step gated on signals:
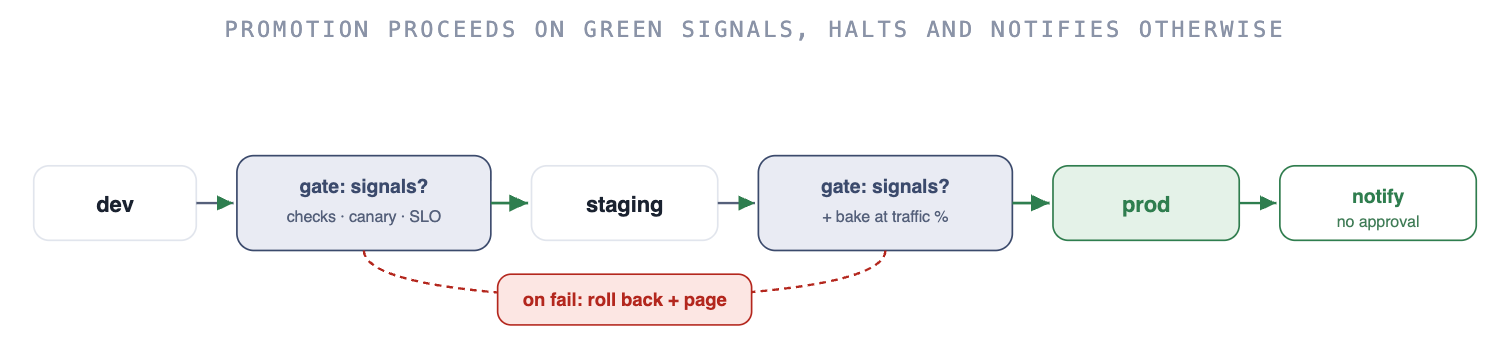
# Promotion gates: each stage promotes only on green signals
staging -> prod:
require:
- checks: green
- canary: healthy for a defined bake at a defined traffic %
- slo: error-budget-burn under threshold
on_fail: roll back the step + page the owner
on_pass: auto-promote, notify (no approval)The principle is human-by-exception: the developer is out of the loop by default and pulled in only when a gate halts, a canary degrades, or an irreversible decision is required. An approval queue a human clicks through is not a gate, it is a rubber stamp with latency; replace the click with a signal. What makes it safe rather than reckless is what each stage validates and for how long: a stage is not “wait five minutes,” it is “observe enough real traffic to distinguish healthy from quietly broken,” so bake time is a function of how long your worst failure mode takes to show up. Automatic means automatic-through-gates, not unconditional.
Orchestrate it with Argo CD and Argo Rollouts on EKS, or GitHub Environments with required checks, fed by the canary and auto-rollback from lever 7. Keep exactly one true manual gate where it earns its place: a final human confirmation for the highest-blast-radius releases, schema migrations and irreversible data changes especially. The failure mode is that gate creeping back onto everything “just to be safe,” which is tier inflation again.
9 Operate from current runbooks, with agent-readable telemetry
In short
Keep runbooks current by making the agent open a PR to fix them after every ops task, and make telemetry structured enough that an agent can diagnose instead of guess.
The moment agents touch ops, the runbook becomes their instruction set, and a stale runbook means the agent improvises in production. The fix closes the staleness gap at its source: the agent that just ran the task is the best-placed author of the correction, and it has no ego about admitting the doc was wrong.
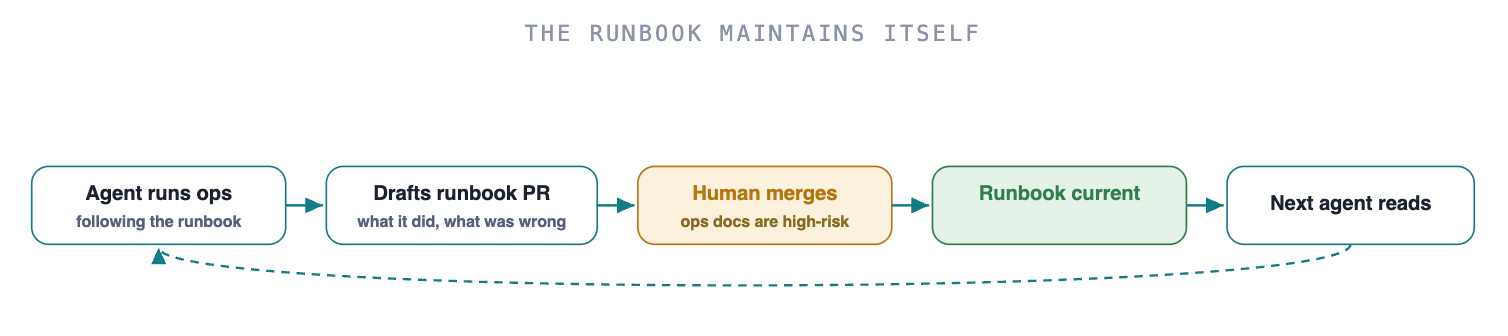
Keep runbooks as version-controlled markdown with explicit steps, and make "open a PR updating the runbook" a required final step of any ops workflow, fired by a Stop hook or a runbook subagent. Make observability agent-readable too, which is a different bar than human-readable:
Reduces the agent to guessing
ERROR: something went wrong
Lets the agent follow the thread
{ "level":"error", "svc":"checkout",
"trace_id":"a1b2", "err":"DBTimeout",
"query":"SELECT ... ", "ms":5031 }
Structured JSON logs, OpenTelemetry traces with real span attributes, and specific queryable errors are what let an agent diagnose instead of speculate. The investment pays off twice, once for your humans and once, larger, for every agent you point at an incident. How the agent is permitted to act on that telemetry is lever 10.
10 Equip agents to run ops safely: read broad, write gated
In short
Let the agent investigate freely on broad read-only access, and gate every mutation behind a brokered, short-lived write credential, with tokens that never enter the prompt.
Lever 9 keeps the runbooks current and the telemetry legible. This lever gives the agent the means to act on them, so a developer can run ops through it, without that access becoming a standing liability. Two halves.
Give it the tools. The instruments a human on call would open: logs, traces, and metrics (an observability MCP server, or Grafana with Loki and Tempo behind one), the build and CI system, read access to the cluster, the deploy history. Expose them as MCP servers with an explicit tool allowlist, so the set of things the agent can attempt is enumerable.
Bound them. The two common failures mirror each other: over-grant with standing tokens, or over-restrict into uselessness. The model that works:
Identity, not secrets. The agent authenticates as a workload identity via OIDC and exchanges it for short-lived, scoped credentials at the moment of use (AWS STS AssumeRoleWithWebIdentity, tens of minutes, one role). Nothing long-lived to steal, the same federation your CI already uses.
Its own identity, scoped to the human behind it. A task credential that is the intersection of what the agent's role permits, what the triggering developer permits, and what the task needs, time-boxed. A junior's agent cannot perform SRE actions, the agent never exceeds the human, and the audit trail names both.
Read broad, write gated, enforced at the credential layer. Investigation (read logs, traces, metrics,
kubectl get) runs on a broad read-only role, no approval. Mutation (deploy, scale, delete, migrate) mints a separate narrow write credential through a just-in-time human approval. Enforce it as two distinct roles, not a prompt instruction, because a prompt is a request and an IAM boundary is a guarantee.Credentials at the tool boundary, never in the context window. The agent calls an MCP tool; the server holds the credential and returns only the result. A prompt injection hidden in a log line cannot exfiltrate a secret the model was never shown.
Egress allowlist. The agent's environment reaches your platform APIs and nothing else, so even a successful injection has nowhere to send what it finds.
Just-in-time approval and clean audit. Irreversible actions surface an approval at the moment. Every action is logged against the agent, the human, and the task, kept clean by one credential issuance per task.
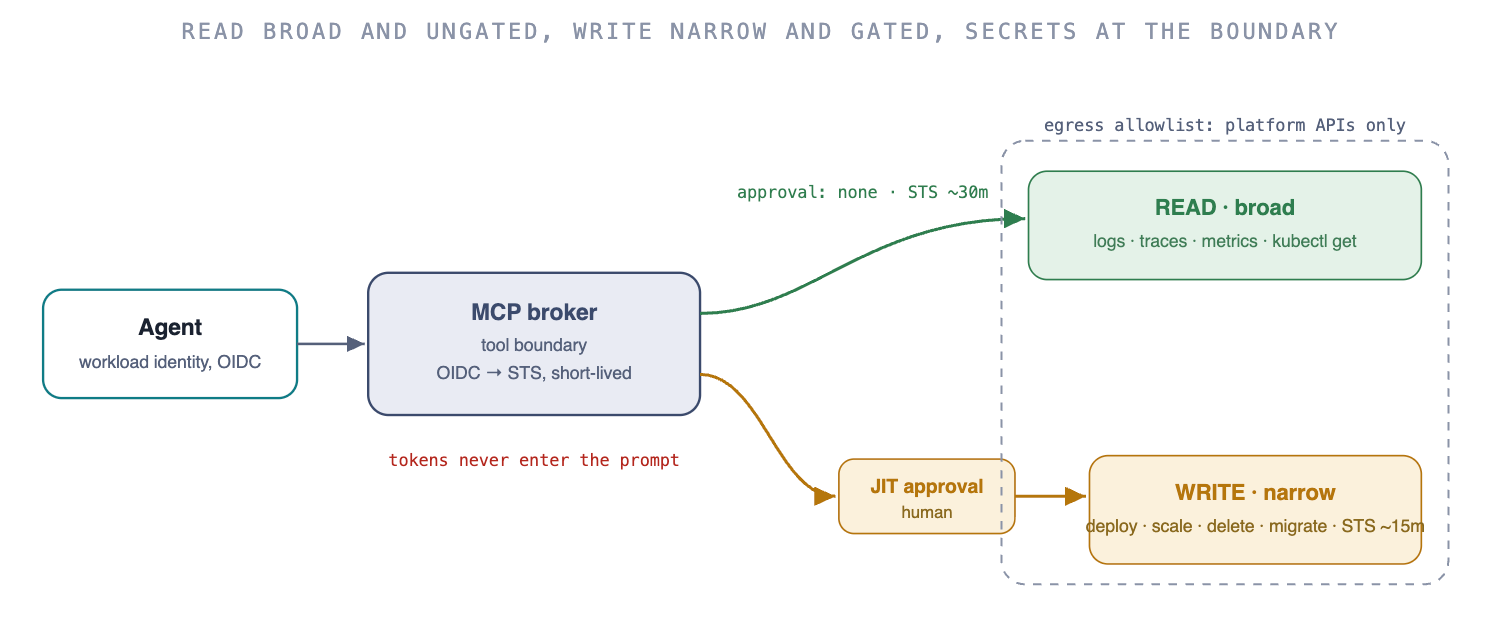
The vault's shrunken job. It holds only the irreducible long-lived secrets, third-party keys that cannot federate, fetched by the broker at call time, never shown to the model, rotated on a schedule. Storing tokens in a vault is necessary but not sufficient: a vault the agent can read freely is just standing credentials with extra steps. The broker, the read/write split, and the egress fence are what actually contain the blast radius.
11 Close the learning loop: reasoning into team knowledge
Inshort
Mine session transcripts, curate the few decisions worth keeping behind a human gate, and feed them back into ADRs and the CLAUDE.md so the loop teaches.
The raw material is already recorded in every session; the tools differ mainly in how easily you extract it.
Extraction is the easy part. The power path on Claude Code is reading the JSONL directly (confirm field names against your version first):
# extract thinking blocks from a Claude Code session
jq -rc ‘select(.message.role==”assistant”).message.content[]?
| select(.type==”thinking”).thinking’ \
~/.claude/projects/<proj>/<session>.jsonl
# Or simply ask Claude code to do it⚠ Version caveat
Recent Claude Code versions hide raw thinking by default to cut latency, and when hidden the transcript does not contain the thinking blocks unless you set showThinkingSummaries: true. Confirm thinking is being written before you build tooling that mines it. (code.claude.com/docs/en/sessions)
The discipline is curation, because raw transcripts are mostly noise. The pipeline that turns sessions into durable knowledge
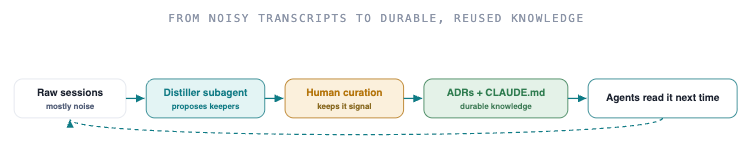
Emit two artifacts at merge: an org-facing record of the decision and tradeoff, and a personal learning note so the engineer keeps growing rather than rubber stamping. Two standing cautions: transcripts are a security surface and can contain secrets, and the 30-day default cleanup will silently eat anything you do not deliberately archive.
12 Keep design human, enforce it in CI
Inshort
Keep humans on design and interfaces and let agents implement within them, then encode the structural invariants so CI enforces them instead of a tired reviewer.
Agents are excellent at known patterns and weak at two things: novel architecture, and the non-obvious simplification a good engineer sees instantly. Left alone they confidently build the elaborate version of something that did not need to exist. So split the work along that fault line:
Humans own
Design, interfaces, the spec. Spec-first: the agent writes or links the design and you approve it before any code, moving your scarce attention to the plan, where the expensive mistakes originate and are cheapest to correct.
Agents own
Implementation within the approved design. Fast, parallel, and bounded by an interface a human chose, so volume does not become architectural drift.
Then encode the design as something CI enforces, because an invariant defended only by review erodes under volume:
# Python, import-linter
[importlinter:contract:layers]
name = Layered architecture
type = layers
layers =
api
services
repositoriesEquivalents: dependency-cruiser (JS/TS), ArchUnit (Java/Kotlin), ts-arch. But be honest about the boundary of the technique:
CI can enforce: Structure, dependency direction, layering, public-API surface, banned imports. The mechanical invariants that protect the human design.
CI cannot enforce Good design, taste, the right abstraction. A passing import-linter run does not mean the architecture is sound, so do not let it stand in for judgment.
Pair the rules with explicit do and do-not guides the agent reads, so the streamlined pattern is the path of least resistance rather than the one it has to be talked into.
13 Treat your agent setup and specs as code
Inshort
Version and test specs, prompts, and agent config like code, budget token spend as a real line item, and never let the quality gates erode just because agents are fast.
The last point is the meta one, and where teams are weakest, because the agent's configuration feels like settings rather than software and so escapes the rigor applied to everything else. Five practices:
Acceptance criteria as tests
Most “the agent did it wrong” incidents are really “the spec was ambiguous.” A failing test is a less ambiguous spec than a paragraph, which is why spec-as-test is also the correctness gate the whole loop leans on.
Version prompts and config like code
Prompts, subagents, and CLAUDE.md live in the repo, reviewed, with history, because they are inputs to production behavior.
Run regression evals in CI
promptfoo, Braintrust, or Langfuse. A prompt change with no eval is a deploy with no test; quality drifts silently until you can no longer bisect why.
Budget token spend
Instrument it as the operational line item it now is, attributed per team and per task, with an alert. An agent with broad tool access and no spend ceiling is a financial blast radius.
Protect main
Do not let branch protections and quality gates erode just because agents are fast. The moment you trade green for fast, you have given the whole game back.
Summary
Lever 1 A self-describing CLAUDE.md generated from source, plus Context7 for current docs
Lever 2 The context window managed as a budget: just-in-time retrieval, compaction, sub-agents, durable memory, integrity
Lever 3 A one-command local verify, flaky tests quarantined, the suite validated as an oracle by mutation testing
Lever 4 Image-layer and affected-build caching, plus a digest-pinned master base image
Lever 5 A monorepo with the remote-cache and affected-graph tooling that earns it
Lever 6 A merge queue with stacked sub-400-line PRs, tiered by real blast radius, not diff size
Lever 7 Flags and canaries with auto-rollback, over backward-compatible state changes
Lever 8 Stepped promotion gated on signals, human by exception
Lever 9 Current, machine-readable runbooks the agent maintains, with agent-readable telemetry
Lever 10 Agents that run ops behind brokered, read-broad write-gated credentials
Lever 11 Transcript mining curated into ADRs and back into context
Lever 12 Design enforced by import rules in CI
Lever 13 Specs and prompts treated as tested, budgeted code
The Bottom Line: Speed Demands a Better Track
You do not need to implement all thirteen levers tomorrow. But you do need to start shifting your platform’s mindset from human-gated to mechanically enforced.
Start small. Stop the bleeding with a self-describing repo. Fix the build so failures are caught locally. Tier your PRs so speed is not scary. The teams that win the next decade of software engineering will not necessarily have the smartest models, they will simply have built the fastest, safest loops around them.
While the agents race. You build the track.