It's a Chunking Lie
Why Sentence Chunking "Wins" Almost Every Benchmark — And Why That Might Be Misleading

Chunking & Why Should You Care?
You have documents & LLMs have token limits. Something has to give for you to RAG it.
That something is chunking — breaking documents into pieces small enough to embed, store, and retrieve. It’s the first real decision in any RAG pipeline, and most tutorials gives less attention that it needs.

Bad chunks mean wrong context retrieved. Wrong context means hallucinated answers. No amount of prompt engineering fixes garbage retrieval.
We might have spent weeks tuning prompts on a RAG system that gave inconsistent results. The problem wasn’t the LLM - it was chunks that cut off mid-sentence, right before the key insight users were asking about.
To answer the question of what is the best way to chunk documents for RAG, I designed a systematic experiment: four chunking strategies, two datasets, thirty configurations, and rigorous evaluation using RAGAS metrics.
The results challenged everything conventional “internet“ knowledge tell us.
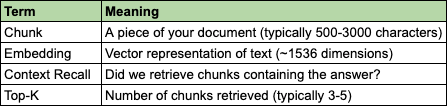
Before we move further - for the uninitiated, here are some key terms to know 👇🏾
Chunking Strategies: A Primer
Let us spend about a minute to understand various “strategies“ we could use to chunk a document.

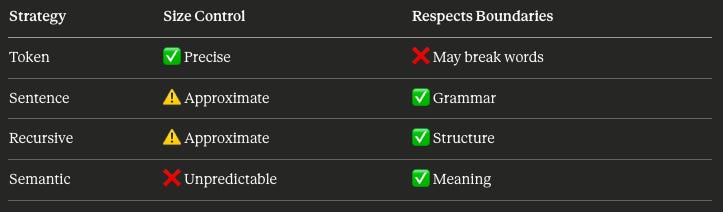
There are four mainstream approaches ☝️ and each makes a different tradeoff
Token Chunking
Cut every N tokens, regardless of content. Simple and predictable — the size you ask for is the size you get. Downside: you might slice mid-word or mid-sentence.
Sentence Chunking
Accumulate sentences until you hit a size target. Respects grammar, so chunks read naturally. The industry favorite — recommended by Redis, Pinecone, and multiple ACL papers.
Recursive Chunking
Split at paragraphs first. If still too big, split at sentences. Then words. Hierarchical and structure-aware. This is LangChain’s default.
Semantic Chunking
Use embeddings to detect topic shifts. Split where meaning changes. Sounds smart, but chunk sizes become unpredictable — you’re letting content decide.
If you want to know more, there are no shortage of articles online. You can even start here.
And as far as the conventional wisdom goes — Sentence and recursive win on intuition — they feel cleaner. Token seems crude. Semantic seems overkill.
Every tutorial you visit or blog you read, you could end up with either “it depends“ or a certain chunking strategy as the best when the article was written.
But, how do you know, what works for the article or the work behind the article, works for you?
The Experiment
We didn’t want to rely on intuition, do we?.
So, I designed an experiment to run the numbers.
The Setup
4 strategies: Token, Sentence, Recursive, Semantic
2 datasets: HotpotQA (3-8K char docs) & natural-questions (96K char docs)
30 configurations across document lengths and chunk sizes
40 queries per configuration, 1200 total retrieval evaluations
Embeddings: OpenAI text-embedding-3-small
Generation: Ollama mistral:7b
Evaluation: RAGAS context_recall as primary metric
All strategies configured with chunk_size=1024. A fair comparison isn’t?
well, well, well. The results confirmed the conventional wisdom
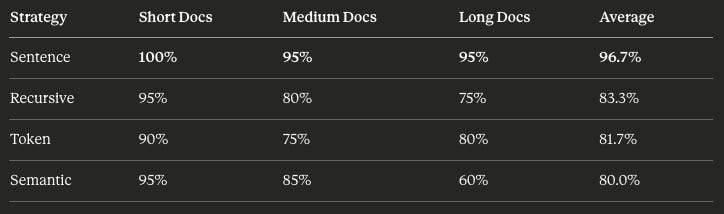
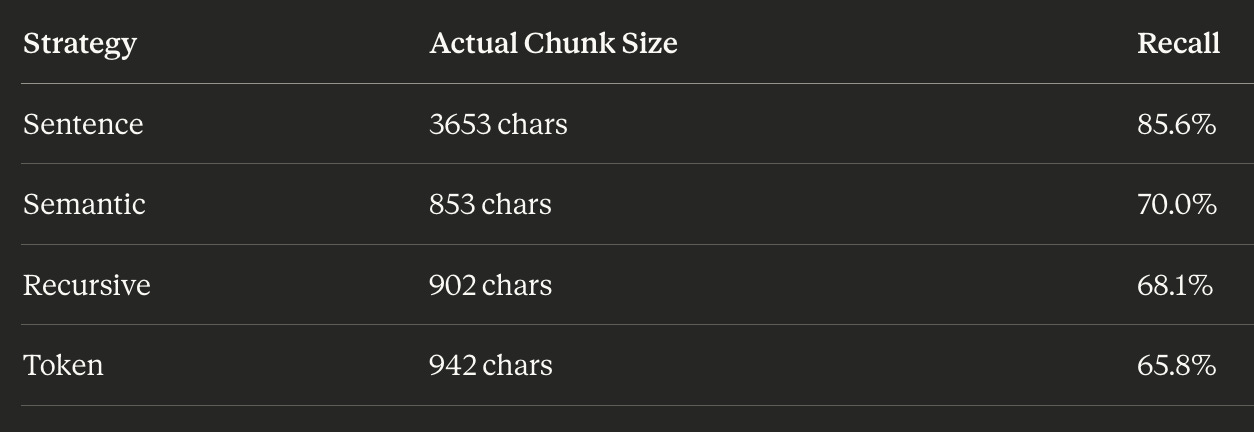
Sentence chunking dominated. Across document lengths, it performed 16% better than the closest contest.
This aligns with the top hits on Perplexity search result as well,
and here is an excerpt
Weaviate – “Chunking Strategies to Improve Your RAG Performance” (2025)
Describes semantic chunking as starting with sentence segmentation, then embedding each sentence and grouping them based on similarity, and recommends this for dense unstructured text like academic or legal documents.Pinecone – “Chunking Strategies for LLM Applications” (2025)
Explains naive sentence splitting vs. more advanced methods, and specifically recommends using sentence tokenizers (NLTK, spaCy) to create more meaningful sentence-level chunks before grouping them.GraphRAG docs – “Text Chunking” (2024)
Lists “Sentence Chunking” explicitly as a strategy and defines it as splitting a document into individual sentences, with separate entries for semantic chunking that also begin from sentences.Microsoft Azure AI Search – “Chunk documents”
Explains chunking options for PDFs/HTML and includes sentence-based and hierarchical approaches that respect sentence and paragraph boundaries as recommended practices for vector search.
Case Closed!!! We have a clear & thumping winner 🥳
Or so I thought 😿.
The Plot Twist?!?
Adding one more column to my analysis. Something that was not obvious in most of my reference material - Chunk size: Not requested chunk size but the Actual chunk size.
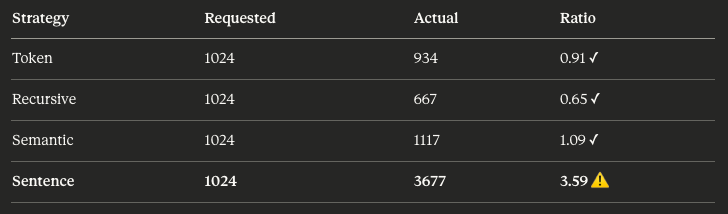
All strategies are configured with chunk_size=1024. Token and recursive respected that and they actually produced slightly smaller chunks. Semantic landed close to target.
Sentence chunking, however, produced chunks 3.6 times larger than requested.
Why This Happens
This isn’t a bug. It’s how LlamaIndex’s SentenceSplitter is designed to work.
The splitter accumulates sentences until it approaches the target size. But it won’t break a sentence in half. If the next sentence would push the chunk over the limit, it has a choice: break the sentence (violating its core principle) or include it anyway (overshooting the target).
It chooses to overshoot. Every time.
With academic text, legal documents, or technical writing, where sentences tend to be long and complex — the overshoot compounds. A 1024-character target becomes 3000+. In our experiment, one configuration targeting 3000 characters produced chunks averaging 8150 characters.
The Confounding Variable
This changes everything about how we interpret our results.
Go back to the experiment table:

Sentence chunking didn’t win because it respects grammatical boundaries. It won because each chunk contained 3-5x more text than the competition.
More text per chunk means more context for the embedding. More context means better semantic representation. Better representation means higher retrieval recall.
This isn’t a discovery about chunking strategy. It’s a discovery about chunking size — hiding in plain sight as a strategy.
The Gap in the Literature
Going back through every source I’d cited:
Weaviate (2025) — recommends sentence chunking, doesn’t report actual sizes produced
Pinecone (2025) — recommends sentence tokenizers, doesn’t report actual sizes produced
GraphRAG docs (2024) — lists sentence chunking as a strategy, doesn’t report actual sizes produced
Microsoft Azure AI Search — recommends sentence boundaries, doesn’t report actual sizes produced
PIC paper (ACL 2025) — compares sentence-based segments to fixed windows, doesn’t control for output size
None of them measure what actually comes out of the chunking pipeline. They configure a strategy, run retrieval, and report results. The implicit assumption is that “chunk_size=xxxx” means roughly comparable chunks across strategies.
That assumption is wrong.
The Question
If chunk size is the real driver — not chunk strategy — we should be able to test it directly.
What happens when we force all strategies to produce similar-sized chunks?
The Controlled Experiment
To isolate strategy from size, I designed a second experiment.
The Design
Instead of configuring all strategies with the same chunk_size parameter, I tuned each strategy to produce approximately the same actual output size.
Target: ~3000 characters per chunk.
Token: Set to 750 tokens (~3000 chars at 4 chars/token)
Recursive: Set to 3000 characters
Sentence: Set to 3000 characters
Semantic: Cannot be controlled — always produces ~1100 char chunks regardless of configuration
Same dataset. Same queries. Same evaluation. The only difference: forcing comparable chunk sizes.
What Actually Happened

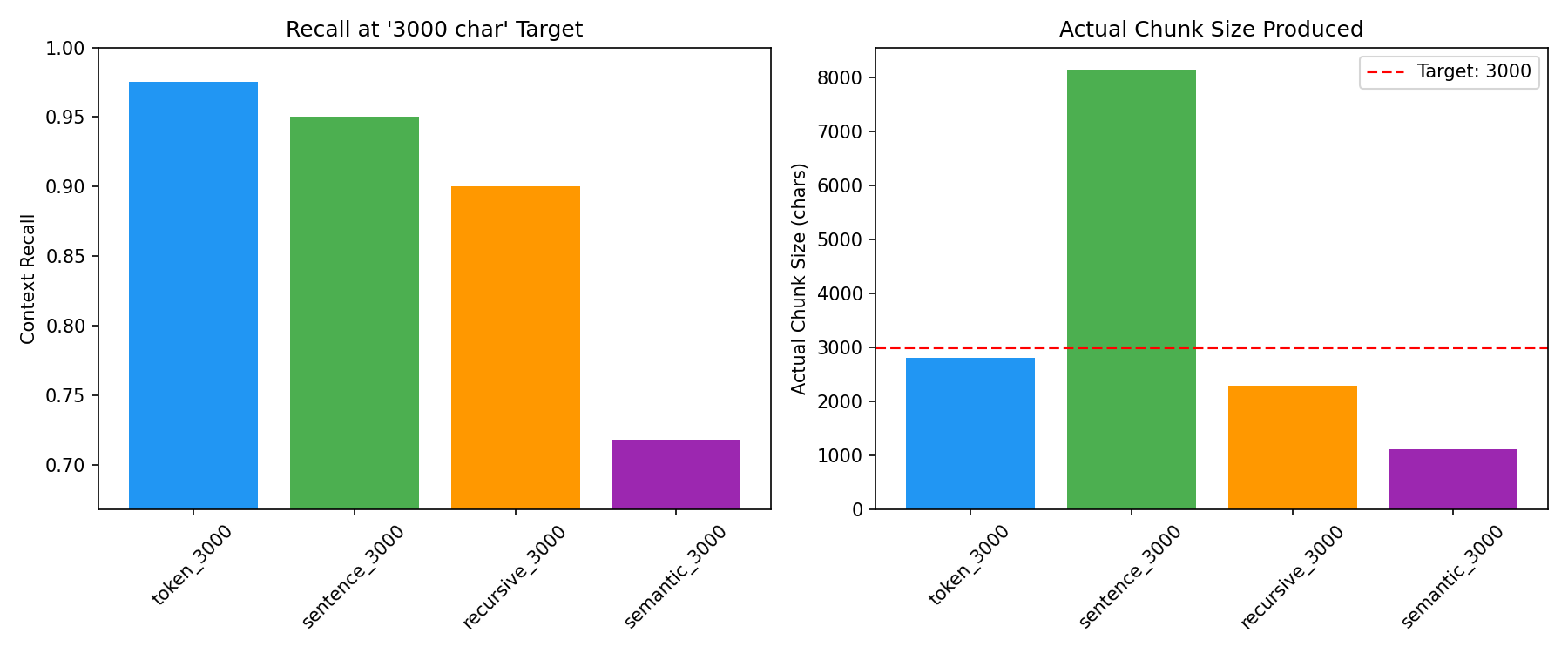
Two things stand out.
First: sentence chunking still couldn’t be controlled. We asked for 3000, it produced 8150. The overshoot problem persists regardless of target size.
Second — and this is the key finding — token chunking outperformed sentence chunking when producing comparable amounts of text.
At ~2800 characters, token chunking hit 97.5% recall. Sentence chunking needed 8150 characters — nearly 3x more — to achieve 95.0%. That’s worse performance with more context.
The Reversal
This inverts the conventional wisdom entirely.

Token chunking isn’t just competitive — it’s 3x more efficient. It achieves higher recall with less than half the text.
What About Smaller Chunks?
The pattern holds at smaller target sizes too:
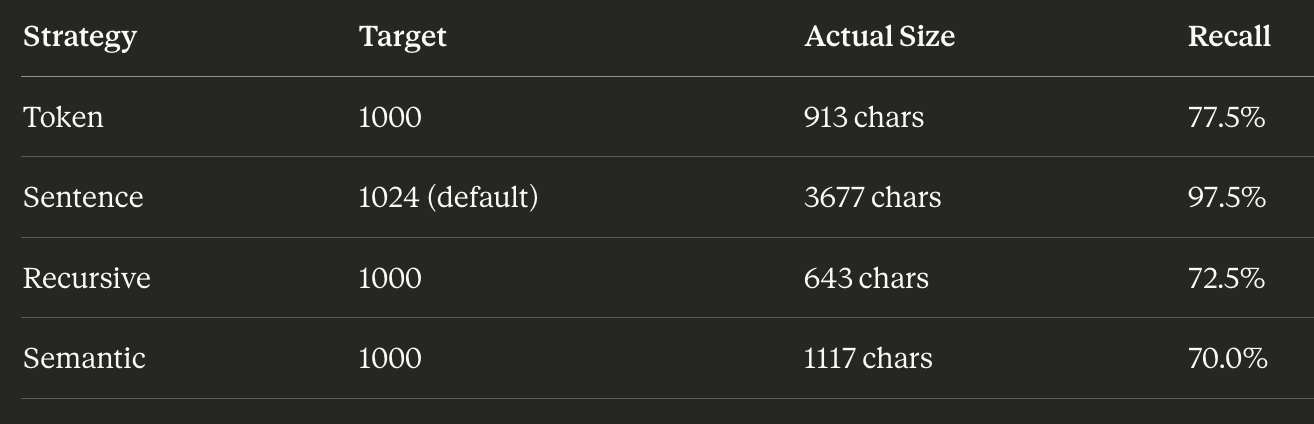
Even when targeting ~1000 characters, sentence chunking refuses to comply — it produces 3677 characters and dominates the recall metric. But token, recursive, and semantic all land in the 600-1100 character range and perform comparably (70-77.5% recall).
The Correlation
To quantify this, I plotted actual chunk size against context recall across all 30 configurations:

Pearson correlation: r = 0.74
On Natural Questions with 96K character documents, the correlation was even stronger: r = 0.92.
A note on statistics: Pearson’s r measures linear correlation between two variables, ranging from -1 to +1. An r of 0.74 indicates a strong positive relationship — as chunk size increases, recall increases proportionally. Values above 0.7 are generally considered strong correlations. An r of 0.92 is very strong, meaning chunk size explains roughly 85% of the variance in recall (r² = 0.85).
Chunk size explains the majority of variance in retrieval performance. Strategy choice is a secondary effect at best.
The Real Finding
Stated plainly:
Chunk size is the dominant factor in RAG retrieval quality. Chunking strategy is secondary.
The scatter plot tells the story. Regardless of whether you use token, sentence, recursive, or semantic chunking — the points cluster along the same trend line. Bigger chunks, better recall. The strategy you choose affects where the boundaries land, but the amount of context per chunk drives performance.
Statistical Significance
To confirm this wasn’t noise, I ran pairwise significance tests on the key comparisons:
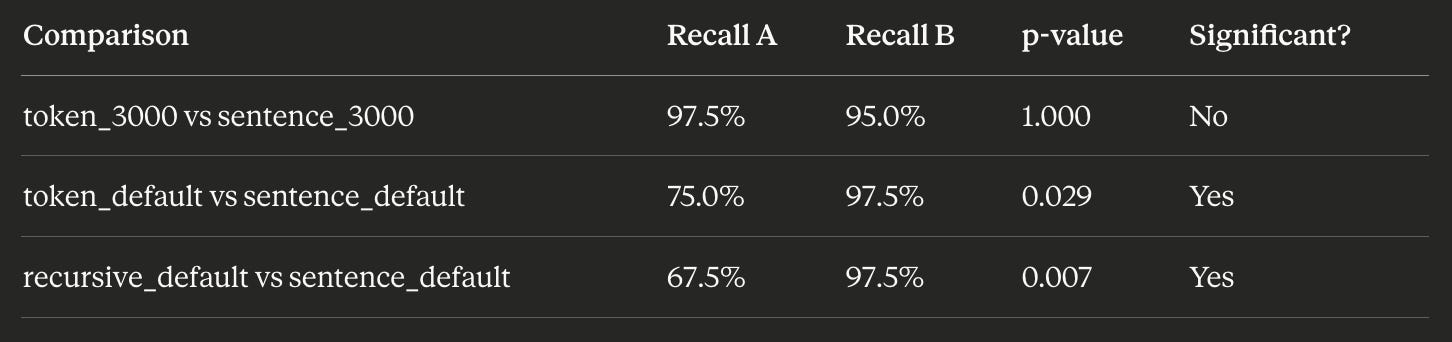
When chunk sizes are similar (~3000 chars), there is no statistically significant difference between token and sentence chunking. The p-value of 1.0 means the results are essentially identical.
When chunk sizes differ (default settings), sentence chunking wins decisively — but we’ve established that’s a size effect, not a strategy effect.
A note on p-values: The p-value indicates the probability of observing results this extreme if there were no real difference between strategies. A p-value below 0.05 is conventionally considered statistically significant. A p-value of 1.0 means the observed difference could easily occur by chance — there’s no detectable effect.
Effect Sizes
Statistical significance tells us if there’s a difference. Effect size tells us how much it matters.
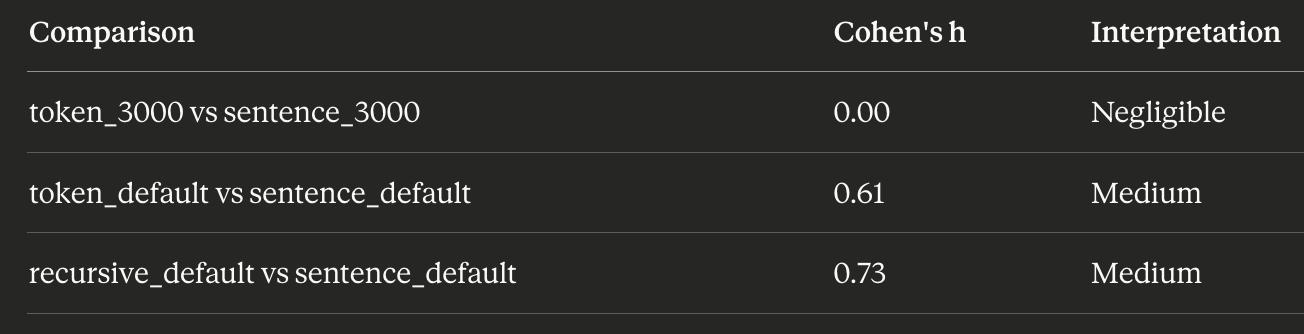
A note on Cohen’s h: This measures the practical difference between two proportions. Values below 0.2 are negligible, 0.2-0.5 are small, 0.5-0.8 are medium, and above 0.8 are large. A Cohen’s h of 0.00 means the strategies perform identically in practice.
At controlled sizes, the effect is zero. The medium effects at default settings disappear once you account for chunk size.
Cross-Dataset Validation
Does this hold beyond HotpotQA? I ran the same analysis on Natural Questions — a dataset with much longer documents (96K characters average).
Same pattern. Sentence chunking produces larger chunks and wins. The correlation between chunk size and recall: r = 0.976.
The Mental Model
Think of it this way:
Chunk size is the volume knob — it controls how much signal gets through
Chunking strategy is the equalizer — it shapes the signal, but can’t compensate for low volume
You can tweak the EQ all day. If the volume is too low, nobody hears the music.
What This Means For You
The findings translate into concrete recommendations.
1. Your Config Is Probably Lying To You
If you’re using sentence chunking with chunk_size=1024, you’re not getting 1024-character chunks. You’re getting 3000-4000 character chunks, sometimes more.
This matters for:
Token costs: Larger chunks mean more tokens embedded and more tokens in your LLM context
Latency: More text to embed, more text to process
Context window budgets: If you’re retrieving top-5 chunks at 3500 chars each, that’s 17,500 characters before you’ve added your prompt
Check your actual chunk sizes. Add logging. Let it surprise you.
2. Start Optimizing Size
The conventional approach: “Should I use sentence, recursive, or semantic chunking?”
The better question: “What chunk size gives me the best recall-latency-cost tradeoff for my use case?”
Based on my experiments:

Once you’ve picked a size, strategy choice is secondary. Use whatever produces chunks closest to your target.
3. Use the Right Tool for Control
Not all strategies respect size parameters equally:
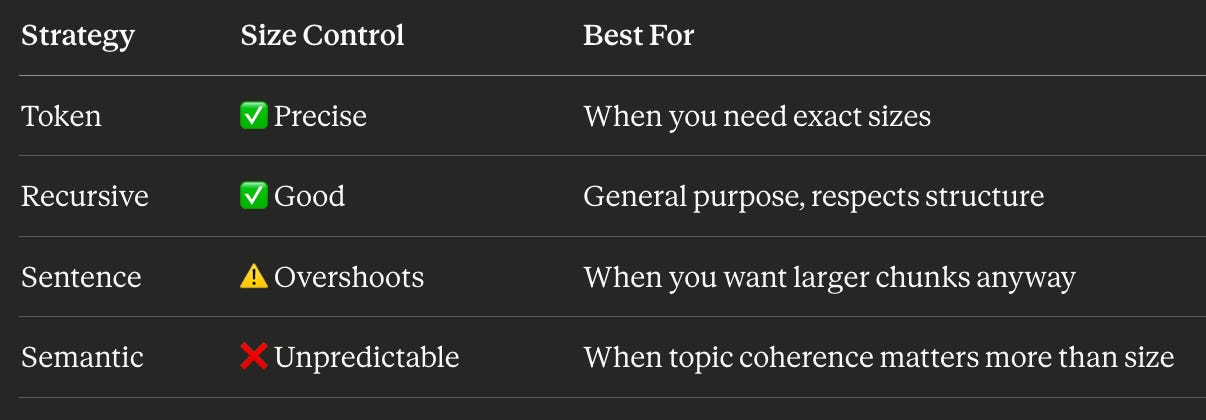
If size control matters to your pipeline, for cost management, latency budgets, or reproducibility & token or recursive chunking gives you predictable outputs. Sentence chunking does not.
4. Measure What Matters
When evaluating chunking approaches, report:
Requested chunk size (your configuration)
Actual chunk size (what was produced)
Retrieval recall (did you get the right context?)
Chunks per document (affects retrieval precision)
Without actual chunk size, strategy comparisons are meaningless. This is the gap in most benchmarks and tutorials and now you know to look for it.
5. When Sentence Chunking Still Makes Sense
This isn’t an argument against sentence chunking. It’s an argument for understanding what you’re getting.
Sentence chunking is a reasonable choice when:
You want larger chunks and accept the size variance
Your documents have long, complex sentences (academic, legal, technical)
Grammatical coherence matters more than size predictability
You’re optimizing for recall and cost is secondary
Just don’t configure it at 1024 characters and assume you’re comparing fairly against other strategies at 1024 characters. You’re not.
Methodology & Code
The findings in this article are backed by a fully extensible experiment framework. Everything is open source and designed for replication and extension.
The Experiment
4 strategies: Token, Sentence, Recursive, Semantic
2 datasets: HotpotQA (3-8K char docs), Natural Questions (96K char docs)
30 configurations across document lengths and chunk sizes
40 queries per configuration, 1,200 total retrieval evaluations
Embeddings: OpenAI text-embedding-3-small
Generation: Ollama mistral:7b
Evaluation: RAGAS context_recall as primary metric
Statistical Tests

Project Structure
chunking/
├── strategies/ # Chunking implementations
│ ├── token.py # Fixed token count (most precise)
│ ├── recursive.py # Hierarchical splits (LangChain default)
│ ├── sentence.py # Sentence boundaries (ignores chunk_size!)
│ └── semantic.py # Embedding-based boundaries
├── datasets/ # Data loaders
│ ├── hotpotqa.py # Multi-hop QA (3-9K char docs)
│ └── natural_questions.py # Wikipedia (96K char docs)
├── configs/ # Experiment configurations
├── results/ # Raw experiment data
├── runner.py # Experiment orchestration
├── evaluation.py # RAGAS metrics wrapper
├── analyze.py # Statistical analysis
└── cli.py # Command-line interfaceReplication
# Clone and setup
git clone [repo-url]
cd rag-experiments
uv sync
# Set environment
cp .env.template .env
# Add your OPENAI_API_KEY
# Pull generation model
ollama pull mistral:7b
# List available experiments
./run.sh chunking --list
# Run all experiments (~6 hours)
./run.sh chunking --all
# Or run specific experiment
./run.sh chunking --experiment document_length
# Analyze results
./run.sh chunking --analyze document_lengthExtension: Adding Your Own Chunking Strategy
Create chunking/strategies/my_strategy.py:
from chunking.strategies.base import ChunkingStrategy
class MyCustomChunker(ChunkingStrategy):
name = "my_custom"
def __init__(self, chunk_size=1024, chunk_overlap=128, **kwargs):
super().__init__(chunk_size, chunk_overlap, **kwargs)
def chunk(self, documents):
nodes = []
for doc in documents:
# Your chunking logic here
pass
return nodesRegister in chunking/strategies/__init__.py:
STRATEGIES = {
"token": TokenChunker,
"sentence": SentenceChunker,
"my_custom": MyCustomChunker, # Add here
}Extension: Adding Your Own Dataset
Same pattern — inherit from the base class, implement load(), register in __init__.py. See chunking/datasets/hotpotqa.py for reference.
Extension: Creating New Experiments
All experiments are YAML-driven:
name: my_experiment
dataset: hotpotqa
dataset_args:
num_examples: 40
min_length: 7000
configurations:
- name: token_2000
strategy: token
chunk_size: 2000
- name: my_custom_2000
strategy: my_custom
chunk_size: 2000
evaluation:
metrics: [context_recall, context_precision]
top_k: 3
num_queries: 40Run it:
./run.sh chunking --experiment my_experimentLimitations
Two QA datasets — results may differ for summarization or classification
Single embedding model — sensitivity may vary across architectures
Fixed top-k of 3 — larger k might reduce chunk size dependency
English only — sentence boundaries behave differently across languages
Code Availability
Full code, configs, and results: GitHub link
What’s Next
This study raises questions I’m actively exploring:
The ceiling: Bigger chunks improve recall — but where do returns diminish? At what size does noise outweigh signal?
Embedding models: Does chunk size sensitivity vary across embedding architectures? Would a larger model change the optimal size?
Top-k and reranking: Can retrieving more chunks or adding a reranker compensate for smaller chunk sizes?
Follow the repo for updates. Contributions welcome.
Sincere thanks to Mahimai Raja for his review of this article.
And subscribe for more data-driven deep dives into the engineering decisions that actually matter.
Thanks for this, like rethinkin a Pilates sequnce.